





AI-Powered Job Discovery Platform with Adaptive Web Scraping
Expert Hours
Expert Team
Months Of Development timeline
Project Background
This solution was built as a devPulse R&D initiative to explore autonomous AI agents for web data extraction and job discovery. The goal was to validate whether agent-based systems could replace traditional scraping pipelines by dynamically adapting to different website structures and data sources.
Success Metrics
Complex challenges require structured thinking. We turn fragmented inputs into clear, actionable direction.
extraction success rate
faster job discovery
Cost per Issue was Reduced
average processing time
The Problem
Organizations and recruitment teams face a fundamental inefficiency when trying to understand job availability across different companies: while job data exists publicly, it is fragmented, inconsistent, and expensive to collect at scale. What appears to be a simple task — “find all open positions at a company” — in practice becomes a time-consuming manual process that requires navigating multiple disconnected sources and interpreting unstructured data, ultimately exposing a set of structural and technical limitations that make traditional scraping approaches unreliable at scale.

Inconsistent Career Pages
Company career pages differ significantly in structure. Some are static HTML, while others are JavaScript-heavy SPAs built with frameworks like React or Vue. In many cases, job data is loaded dynamically via hidden APIs. Because of this variability, no single scraping approach works reliably across all websites.

Missing Critical Data
To query external job boards effectively, the system needs accurate company metadata, especially the exact company name and operating regions. However, this information is rarely available directly from a URL or career page and often must be inferred from unstructured sources.

Multi-Step Dependency Chain
The process is inherently sequential. It starts with identifying the structure of the career page, then selecting the appropriate scraping method, extracting and normalizing company data, and finally querying external job boards. Since each step depends on the previous one, traditional rule-based pipelines are fragile and fail easily in real-world conditions.
DevPulse designed and implemented a self-adaptive AI agent capable of reasoning, experimenting, and dynamically adjusting its approach in real time. Instead of relying on hardcoded logic, the system continuously adapts its scraping and search strategies based on observed results, enabling it to handle failures gracefully, consolidate data from multiple sources, and produce structured, reliable outputs.
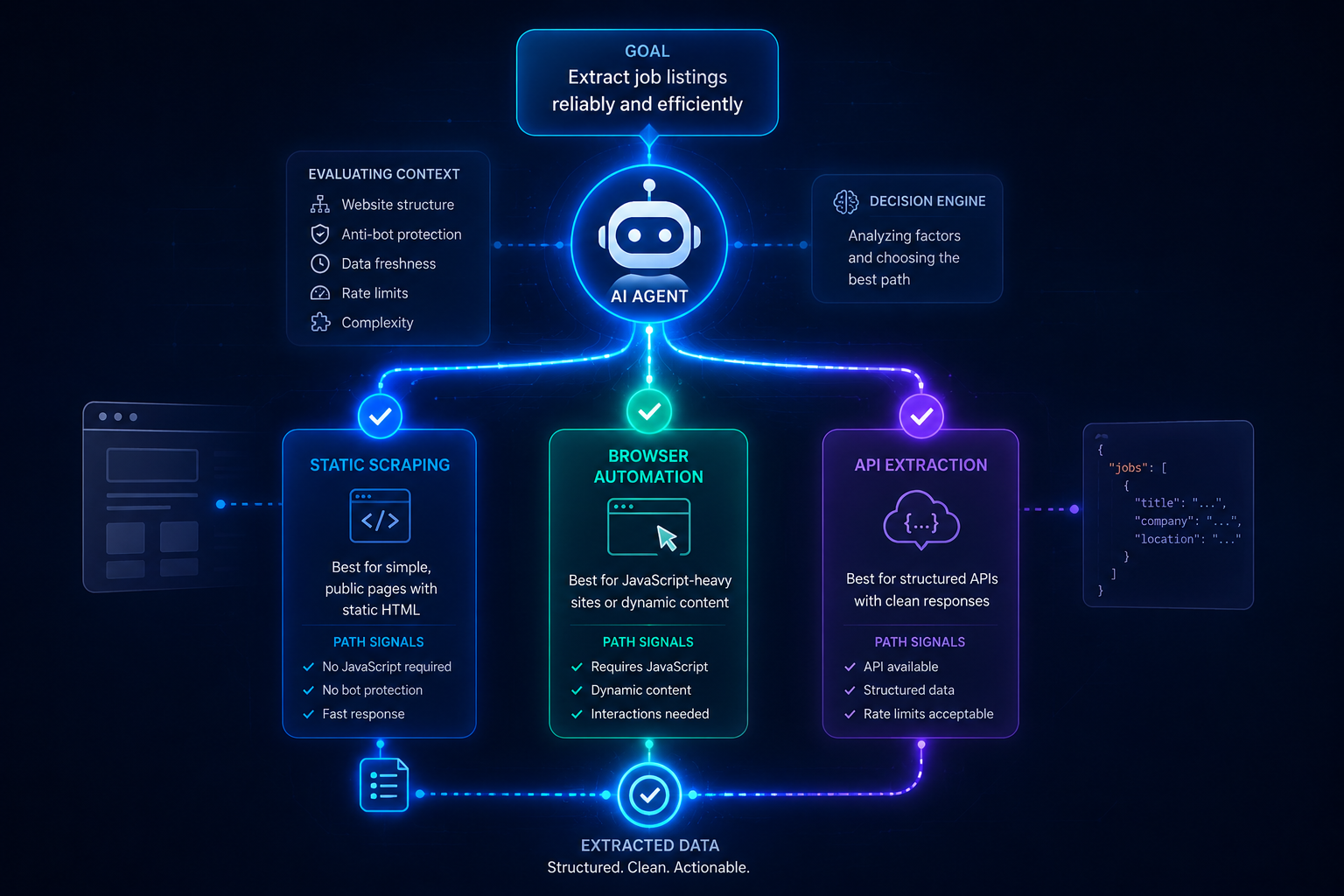
AI Agent Architecture
The platform is powered by a modular agent built with LangGraph, structured as a transparent and controllable state machine. Core components:
Case attributes
Partnership period
2024-2025
Team Composition
ML Engineer
Product Owner
Location
Ukraine
Technology stack
Agent orchestration
LLMs
Scraping
Job data aggregation
Backend
Queue system
Database
Infrastructure
Next.js
LangGraph
OpenAI GPT-4.1, OpenAI GPT-4o-mini
Playwright, Scrapy
jobspy
Django REST Framework
Celery + Redis
PostgreSQL
DigitalOcean App Platform
Platform
Web
Smart Decision-Making with System Prompting
Instead of embedding orchestration logic directly into code, devPulse centralized the decision-making process within a carefully designed system prompt. This approach enables the agent to dynamically select the appropriate scraping method based on the context, correctly interpret different types of responses such as listings, metadata, or navigation pages, and adjust its behavior when a chosen strategy fails.
A key innovation: The agent is required to explicitly state what it learned and what it will try next before every action.
This structured reasoning significantly improves system reliability, makes execution flows easier to debug, and increases overall transparency of the decision-making process.
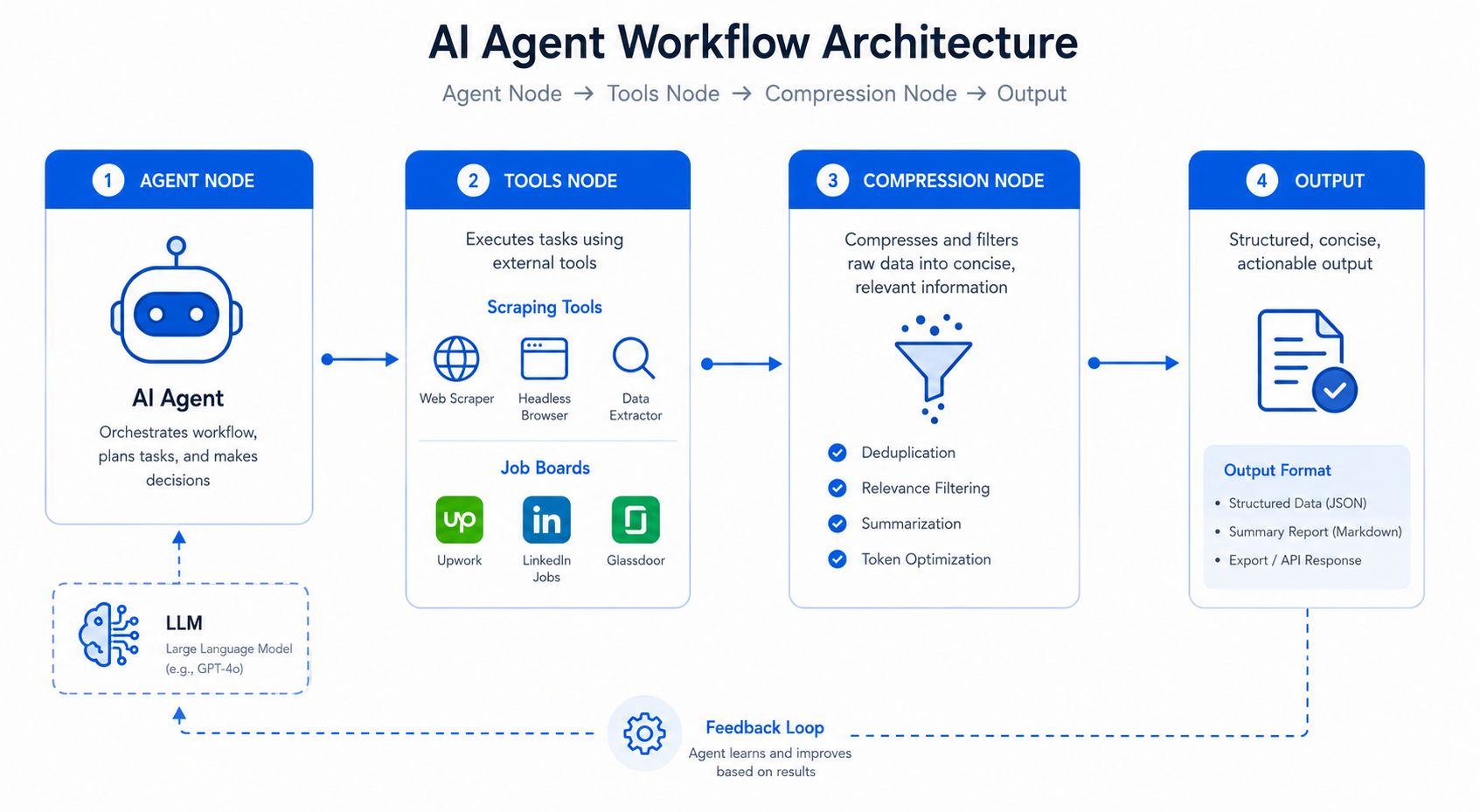
Handling Large-Scale Data with Intelligent Compression
Career pages can contain tens of thousands of characters, quickly exceeding LLM context limits and making direct processing inefficient. To solve this, devPulse built a multi-stage compression pipeline that reduces data size while preserving key structure and meaning.
Compression is first applied at the tool level before data reaches the agent, ensuring only reduced and relevant payloads are processed. This is followed by field-level summarization, which compresses data per source while keeping URLs and structure separated. For larger inputs, recursive chunking is used to split content into smaller parts, summarize them independently, and merge results step by step. The system is further optimized using multiple models, including GPT-4.1 for reasoning, GPT-4o-mini for fast compression, and GPT-4.1-mini for final refinement. As a result, the system significantly reduces token usage while preserving critical signals such as job titles, URLs, and structure, leading to more stable and efficient agent performance at scale.
Key Engineering Decisions
The system was designed around a set of core architectural principles that prioritize adaptability, maintainability, and scalability in real-world scraping environments.
Adaptive Agent over Static Pipelines
The system uses a dynamic reasoning-based agent instead of fixed workflows, allowing it to adjust its behavior in response to real-world variability.
Compression at the Right Layer
Data is compressed before entering the agent context, ensuring that reasoning quality is preserved while reducing token overhead and noise.
Specialized Tools over a Single Scraper
Rather than relying on one universal scraper, the system uses multiple specialized extraction strategies (static scraping, dynamic rendering, network-level interception) to ensure reliable fallback across different page types.
Clear Separation of Concerns
Tools define capabilities, while the system prompt defines orchestration logic, creating a clean boundary that improves maintainability and system evolution.
The Result
The platform enabled fully automated job discovery across multiple sources, significantly reduced manual research effort, and improved data accuracy through multi-source aggregation while maintaining a scalable architecture adaptable to different websites and formats.
More importantly, it demonstrated that AI agents can effectively replace brittle scraping pipelines by introducing adaptive, reasoning-driven workflows that operate reliably in real-world conditions.
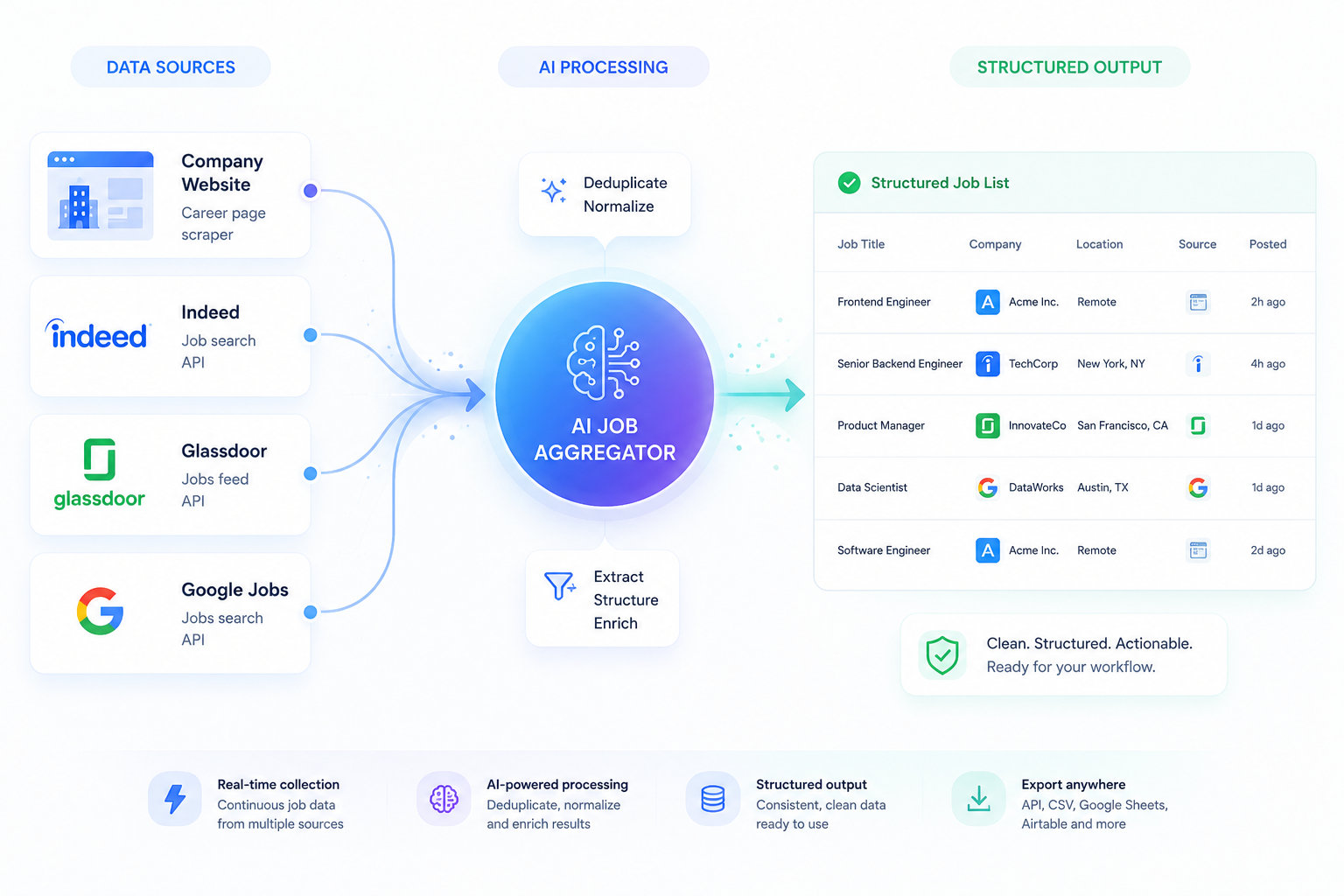
Value Delivered by devPulse

Delivered a fully AI-driven solution that automatically discovers and aggregates job listings across multiple sources without manual configuration or fixed rules.

Eliminated the need for manual research and multi-source job checking, significantly reducing the time required to gather structured hiring data.

Improved accuracy of extracted job information through multi-source validation and intelligent aggregation of inconsistent web data.

Built a modular, agent-based system capable of adapting to new websites, structures, and data sources without re-engineering core logic.

Enabled dynamic selection of scraping strategies based on page structure, ensuring robust performance across static, dynamic, and API-driven websites.

Delivered a system combining LLM orchestration, tool-based architecture, and compression pipelines, suitable for real-world, high-volume usage scenarios.





