






Bulk File Renaming System for High-Volume Data Processing
Expert Hours
Months of Development
Expert Team
Client Background
The client is a Canada-based technology company focused on creating advanced software solutions to help users repair, optimize, and maintain their computers for long-term performance and reliability. Founded with a user-first philosophy, the company’s mission is to make PC care simple, accessible, and effective for everyone — from everyday users to IT professionals.
Success Metrics
From complexity to clear decisions. Clarity, speed, and predictability — without assumptions.
files processed in a single operation
reduction in manual file management effort
faster file organization workflows
repeatability of file transformation rules
Services used
Product development
Quality Engineering
Process Automation
Problem Background
Our client faced significant challenges in managing and organizing large datasets, as manual file renaming was time-consuming and error-prone, inconsistent naming conventions led to data fragmentation, and existing tools were unable to handle bulk file renaming at scale. The lack of automation further slowed down data processing workflows, and as data volumes continued to grow, these issues resulted in operational bottlenecks and reduced overall productivity.
Business challenge
The goal was to create a safe, flexible, and high-performance bulk file renaming system integrated directly into the main application.
This system needed to handle complex naming rules while providing real-time feedback and guarantees against filename collisions or invalid outputs.
Specific challenges included:
Supporting multiple rule combinations to cover advanced renaming logic
Preventing duplicate or invalid filenames across directories
Allowing real-time previews so users could verify results before applying changes
Ensuring scalability for thousands of files without blocking the user interface
The Solution
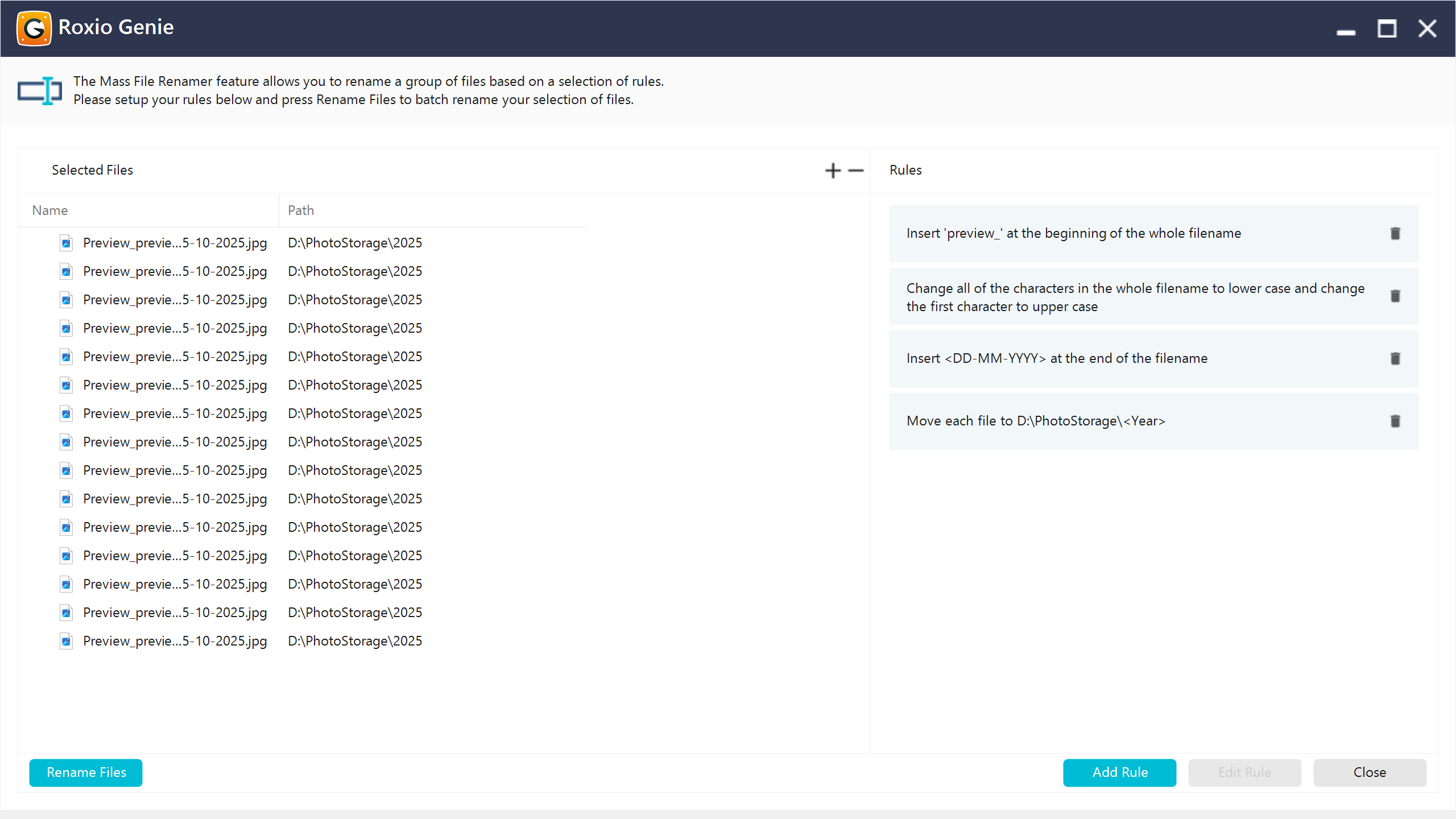
We developed a bulk file renaming system with rule-based automation, enabling the client to efficiently rename thousands of files in seconds while maintaining consistency and control.
The solution allows users to define flexible rules and apply them across large datasets, ensuring standardized file naming without manual intervention.
How It Works
While this architecture delivers robust functionality and stability, it creates natural limitations when adapting to modern, web-based delivery models.
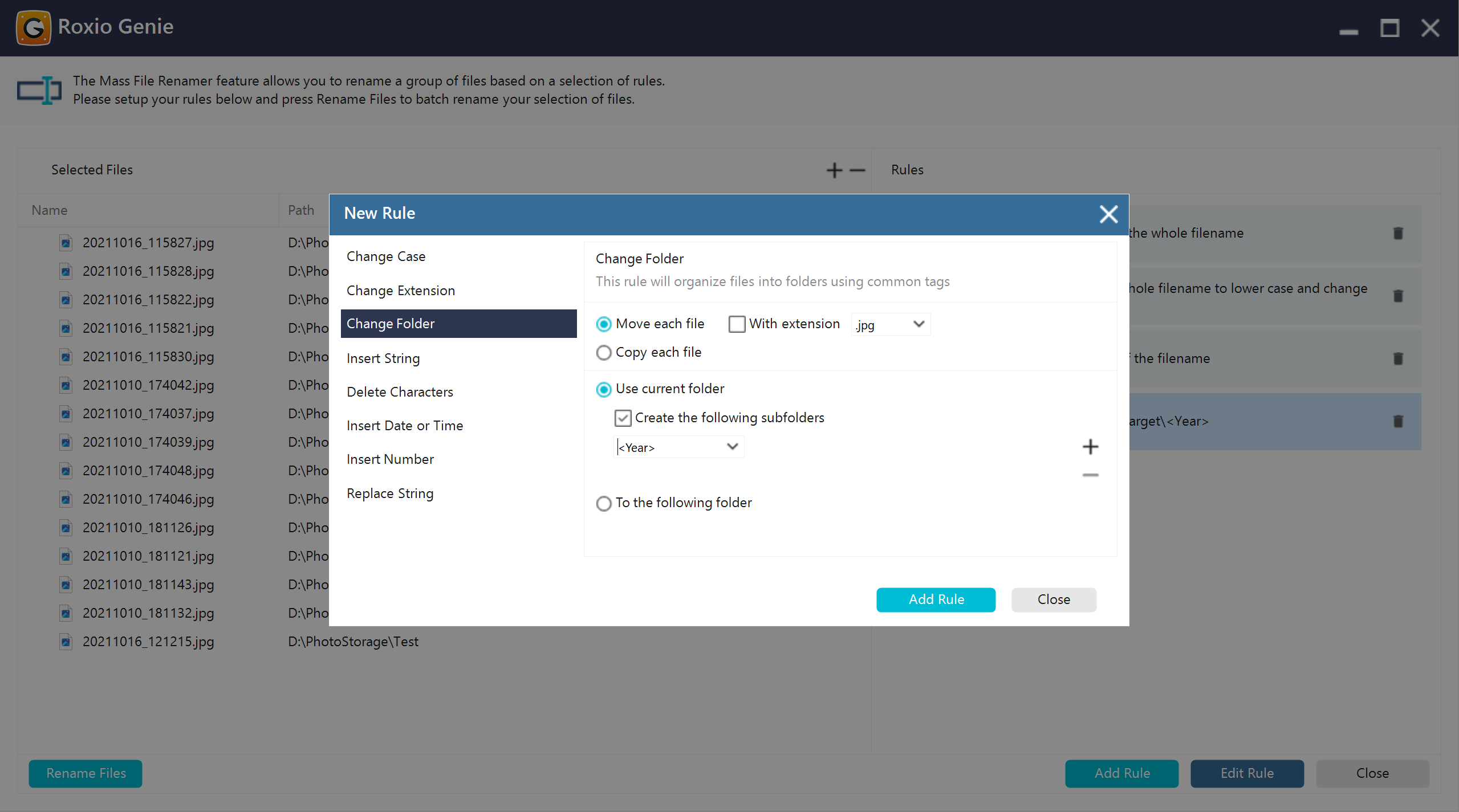
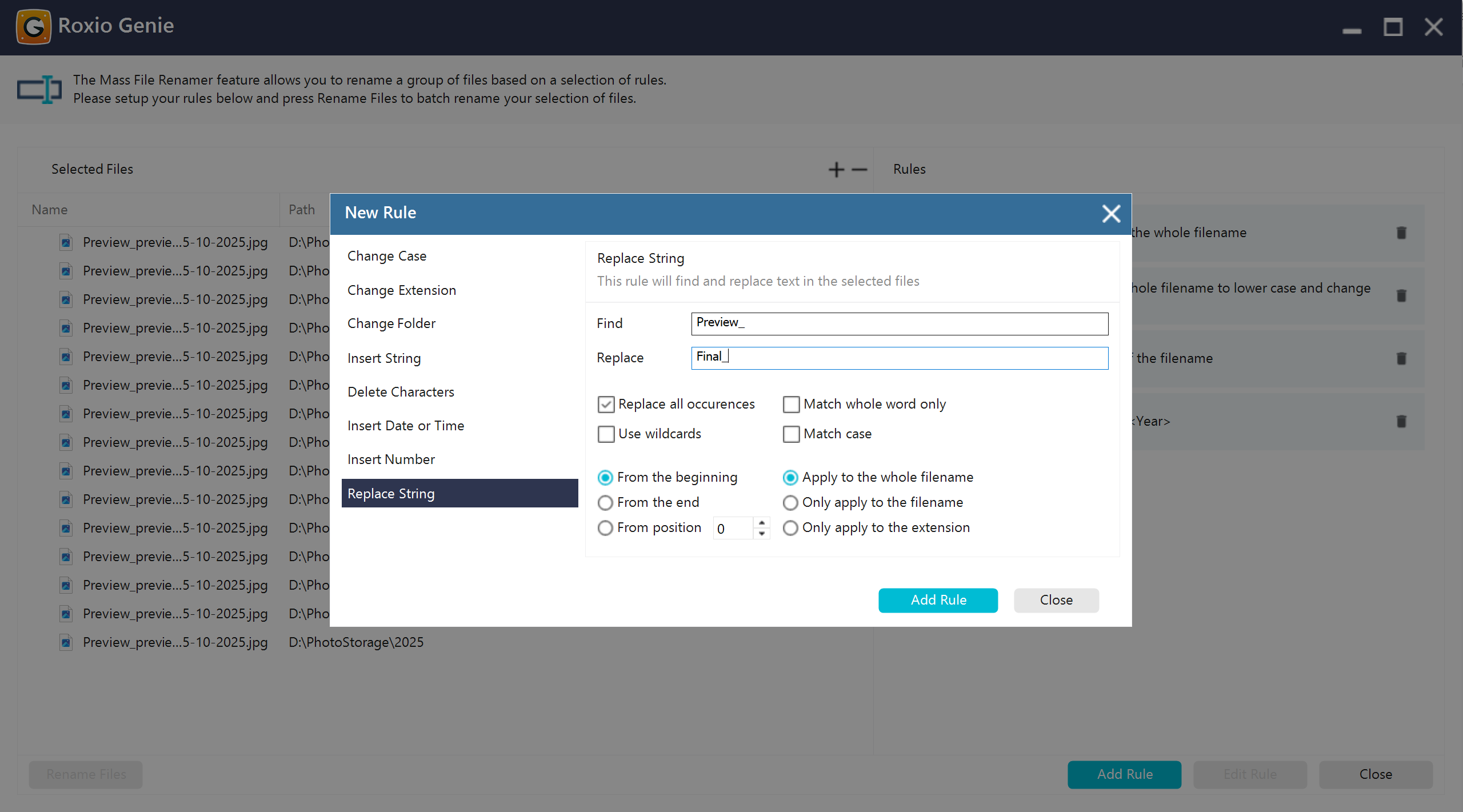
Replace or modify parts of file names
Enables targeted text substitution within file names to quickly standardize or correct naming patterns.
Add prefixes or suffixes
Allows consistent tagging of files by appending or prepending predefined strings to file names.
Change letter casing
Supports normalization of file names by converting text to uppercase, lowercase, or title case formats.
Insert dynamic values based on patterns
Generates file names using contextual or rule-based variables such as timestamps, indexes, or metadata.
Apply multiple rules in a single operation
Combines several transformations into one execution flow, ensuring efficiency and reducing manual steps.
Key Technical Decisions
To ensure performance and scalability, the system was designed with the following principles:
Efficient batch processing
The engine processes large numbers of files in optimized batches, minimizing system load and ensuring fast execution even with thousands of files.
Rule-based architecture
A flexible rule engine allows users to define and combine multiple transformations, making the system adaptable to various file naming scenarios.
Non-blocking operations
Background processing ensures that large renaming operations do not impact system responsiveness.
Scalable design
The architecture supports increasing data volumes without degradation in performance.
Simplify your workflows and automate the way you handle files.
The Result
The solution significantly improved file management workflows by enabling automated bulk file renaming at scale, reducing manual effort, and eliminating naming inconsistencies across large datasets.
As a result, the client achieved faster data processing, improved data organization, and increased overall operational efficiency.
Business Applicability
This solution was designed for enterprise and data-intensive business environments where efficient file organization, consistency, and automation are critical for operational performance and scalability.
Applicable for:
High-volume file processing environments
Suitable for organizations that generate and manage large numbers of files daily, where manual processing is inefficient and does not scale.
Enterprise data and asset management systems
Applicable in structured data environments where consistent naming conventions are required to ensure data integrity, traceability, and easy retrieval across teams and systems.
Standardization across distributed teams
Helps organizations maintain unified file naming practices across departments, reducing fragmentation and improving cross-team collaboration.
Automation of operational file workflows
Eliminates repetitive manual tasks in file management processes by introducing rule-based automation that improves speed and reduces human error.
Value delivered by DevPulse

Looking to automate file management or streamline your data workflows?
Let’s design a scalable solution tailored to your needs.






